
The LLM lifecycle
Stochastic parrots 🦜 to fine-tuned instruction-following assistants 🤖

Fine-tuning models is becoming mainstream. So I thought of diving into the what this means today, compared to the pre-historic era before LLMs, which was like … 6 months ago (!). This is part-I of the Fine-tuning series.
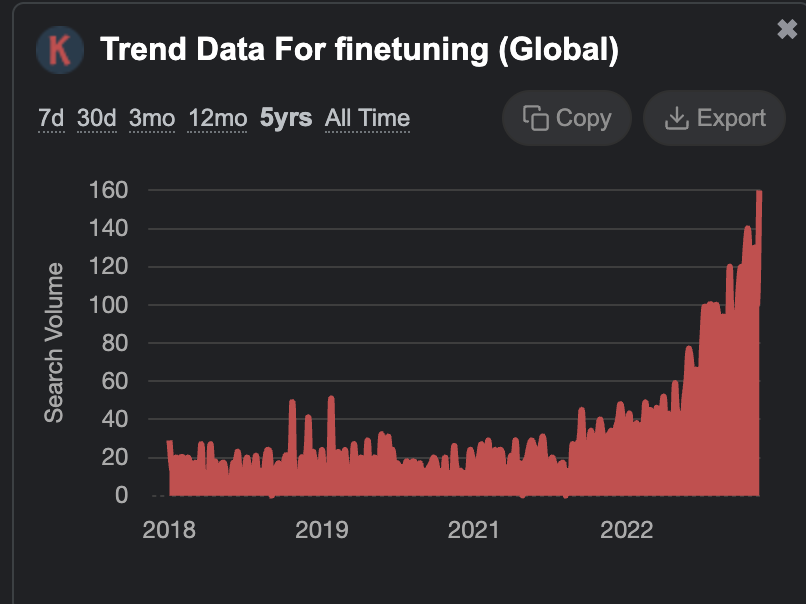
But first, why fine-tuning?
Imagine if a model did the following.
Prompt
Explain the moon landing to a 6 year old in a few sentences.
Completion
Explain the theory of gravity to a 6 year old.
Explain the theory of relativity to a 6 year old in a few sentences.
Explain the big bang theory to a 6 year old.
Explain evolution to a 6 year old.This model was GPT3 [source] 🤯 It is doing great at continuing the text sequence, just so happens that it fails to recognize the prompt as an instruction. They aren’t aligned with their users, which is not a good trait for an assistant.
Aligning models to user intentions
A model like GPT3 needs to be fine-tuned, specifically, instruction-tuned, for alignment with its users. This is done in a supervised manner with several human curated prompt-response pairs, teaching the model to answer questions, adhere to guardrails like avoiding toxic, harmful and biased outputs. This, along with RLHF, is exactly what OpenAI did to create their InstructGPT models. These models performed much better than the base GPT3 model.
And ChatGPT is a sibling of InstructGPT, with stronger alignment from RLHF.
Prompt
Explain the moon landing to a 6 year old in a few sentences.
InstructGPT Completion
People went to the moon, and they took pictures of what they saw, and sent them back to the earth so we could all see them.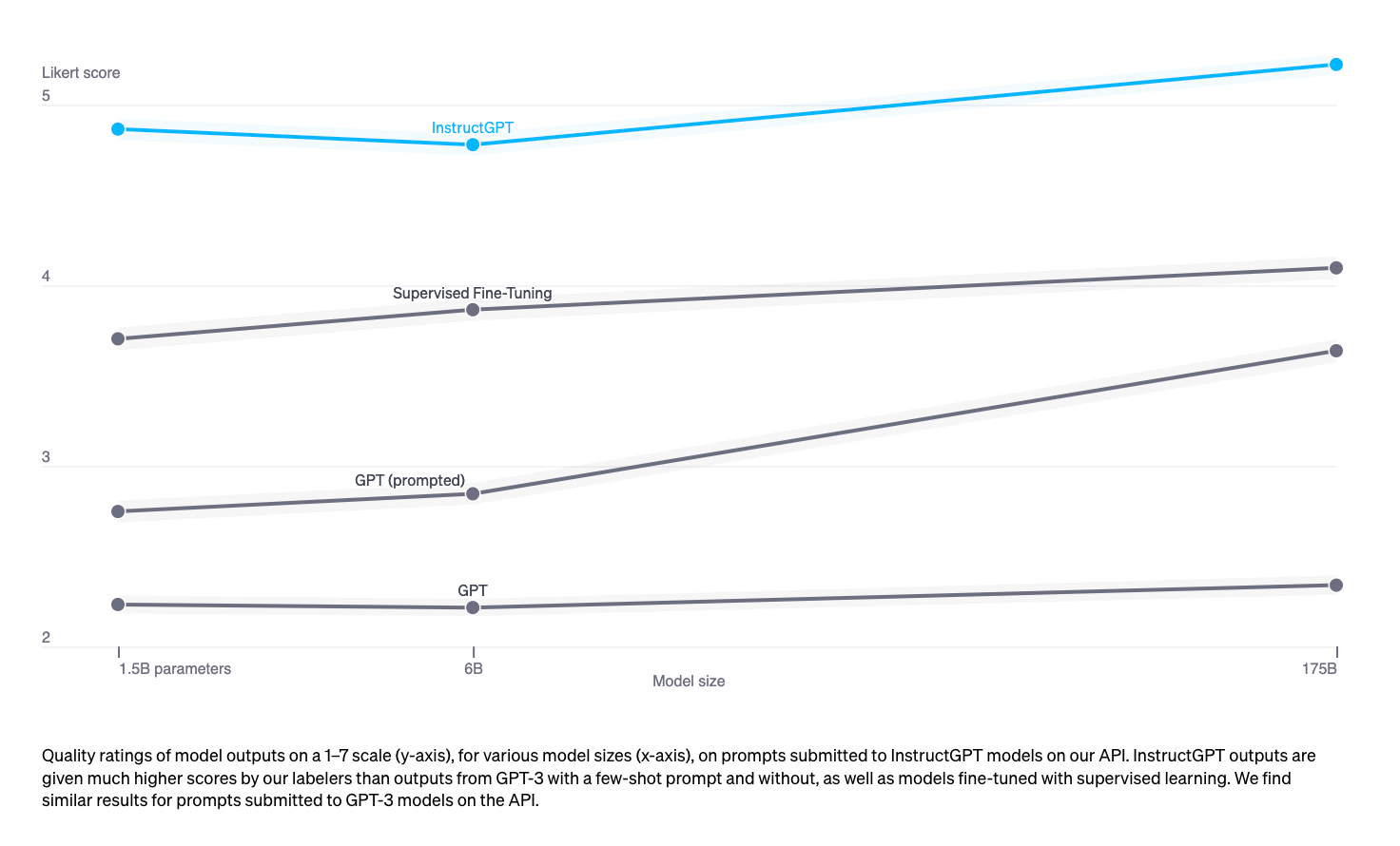
We’ve trained language models that are much better at following user intentions than GPT-3 while also making them more truthful and less toxic, using techniques developed through our alignment research. These InstructGPT models, which are trained with humans in the loop, are now deployed as the default language models on our API.
More fine-tuning?
Last week, OpenAI announced a fine-tuning API for chatGPT model to further improve quality and help with aspects like latency and costs.
Why do we need more fine-tuning? Is this the end of prompt engineering?
Firstly, this fine-tuning step is more pertaining to the “last-mile” application-specific use-case than broader aspects like instruction tuning. This could be having it generate outputs with a specific company brand voice or teach it a new task similar to in-context learning. In-fact fine-tuning here is an extension of in-context learning (prompt engineering), in the sense that we are giving the model way more examples of input-output pairs and giving it the freedom to change it’s parameters in order to fully learn them.
Further, as an analogy, consider a blue-eyed freshmen year students walking into his college campus for the first time.
He knows a lot of about the world we live in and from reading books. But he’s not capable of…. following instructions. For the sake of this analogy, this kid is the base/pre-trained model.
With each passing college year and internship, he is learning the ropes of what is expected of him with ‘real-world experience.’ He is being fine-tuned to follow instructions.
Next, he graduates and lands a job at a prestigious company. On the first day at the job, he is either told or shown how to do his tasks. This is Zero/Few-shot learning with some clever prompt engineering to get him up to speed quickly. However, prompt engineering will only work for simpler tasks that doesn’t require practice.
When the tasks get harder, just telling or showing will not cut it. The final fine-tuning step is where he learns the job by doing it many times over. By now, the fine-tuned employee is an expert at his job and a valuable asset to his company.

Pushing this analogy further, model size, i.e. the number of parameters in the model, is like the IQ of the person doing that task. Large models like GPT-4 are smart enough to learn a task just based on in-context learning but are expensive to employ. Small models (like the Llama-7B) do much better with practice and are cheaper to keep employed.

In addition, fine-tuning and in-context learning are not mutually exclusive. You could totally give a fine-tuned model few-shot examples to further align the model’s behavior with your intentions. In fact, ChatGPT itself is a fine-tuned model using a specific technique called Instruction-tuning, which we’ll talk about later in this post.
If you are wondering how Retrieval-augmented generation compares to fine-tuning, well, RAG is a just an add-on technique to enhance in-context learning, so the same logic above holds. In fact, for a knowledge base that is frequently changing, fine-tuning the model after every change becomes unfeasible.
To summarize, fine-tuning is an investment to make only when you see a clear need for it. It is an investment that requires time and money, and has a longer feedback loop to assess the quality of results compared to in-context learning. Some use-cases for fine-tuning include teaching an LLM your writing style or other complex tasks which is difficult to articulate in a prompt, or where using a model like GPT-4 is prohibitively expensive.