
RAG- Part II
Retrieval Augmented Generation

This is Part II in the RAG series. Find the previous posts here 👇
Part I - Retrieval Augmented Generation (RAG) - I
If you dig and sort through the gazillion AI apps in the market today by real-world utility, production-readiness and revenue-generating capacity, there is a high chance that RAG ranks near the top as the common underlying tech across the successful apps.
Use-cases span customer support (chatbase.co, sitegpt.ai), education (pdf.ai, explainpaper.com), internal knowledge base or documentation search (mendable.ai) and a long tail of niches like legal contracts, notion databases, gmail readers etc.
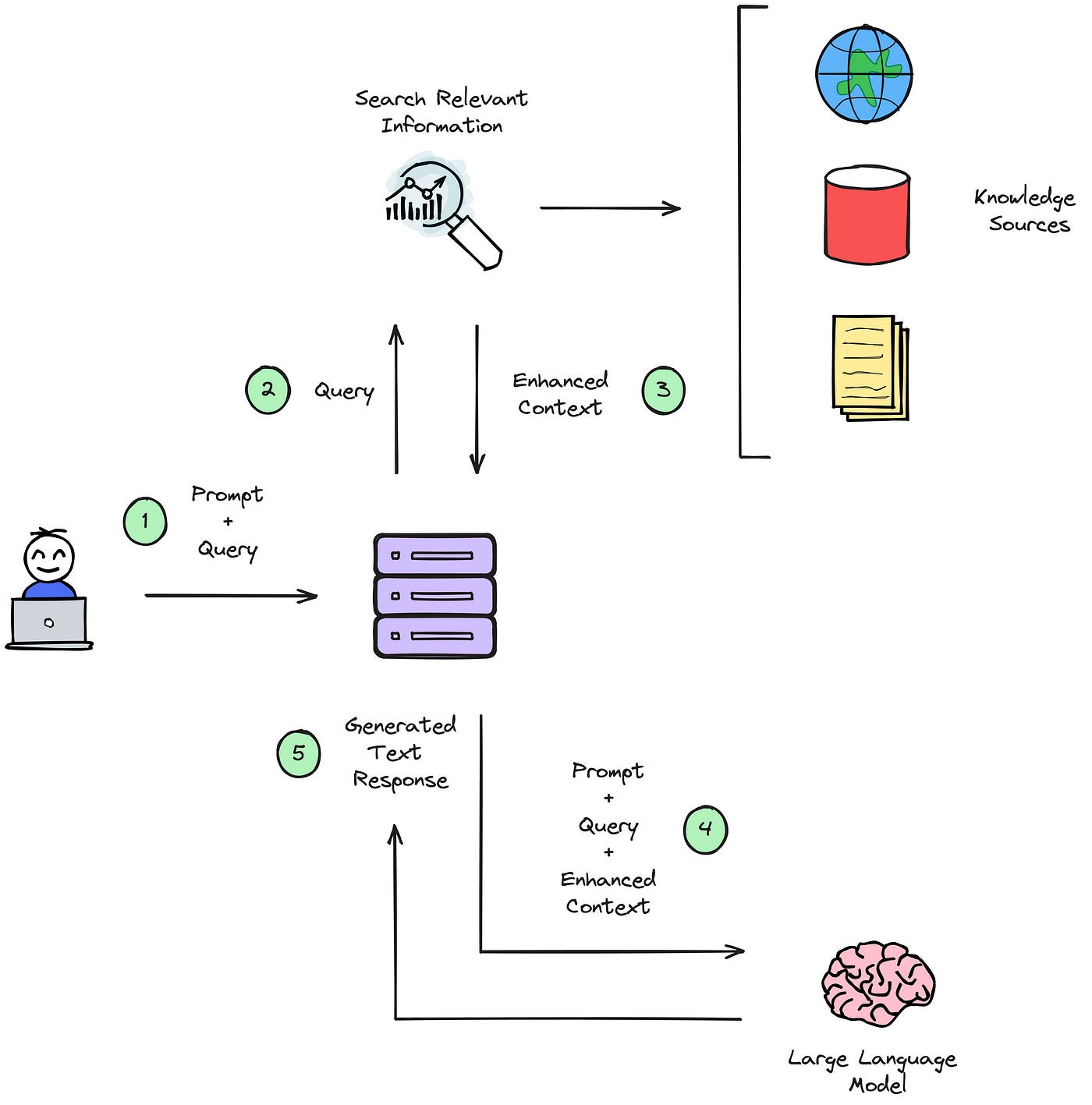
So what is it? It is ChatGPT that knows about *any* text-based documents you show it, which ChatGPT itself has no knowledge of (like a user manual for brand new gadget you purchased but now clueless about getting it work). A RAG can fetch relevant data to your questions from an external knowledge source, share with the LLM which can then take all the credit for knowing the answer.
A RAG is like a loyal wingman to the LLM ✊
My first gig in freelancing was building a chatbot over Notion DB containing technical articles, where the client wanted to expose this resource to their clients in a less intimidating way. AI Chatbots benefit from being technologically located squarely in the intersection of a widely-known and used tool (chatbots) and a brand new technology (AI).
RAG addresses the biggest shortcomings of using LLMs-
not being able to expand or revise memory beyond its training cutoff
not providing sources for generated outputs, and hallucinations
limited context window which makes most documents too big to fit in the prompt for the LLM
Phew… trying passing these risks over to a business owner considering using your LLM-chatbot service.
In contrast, RAG enhances LLMs by -
being accountable and reducing hallucination by grounding the model on provided sources
being cheaper/simpler to update a knowledge base with embedding-based indexing and reflect changes immediately in end-product than to continuously pre-train/fine-tune an LLM
easier to debug in case of erroneous responses through tuning retrieval parameters like document chunk size, similarity scores etc
In Part-III, I’ll share more about my experience with building RAG-chatbots for clients, debugging RAG workflows, evaluating and benchmarking performance.
Stay tuned..